Fondements algorithmiques
La plateforme SDM'Studio est construite autour de la généricité des schémas algorithmiques de planification et d'apprentissage par renforcement. Les schémas algorithmique natifs de la plateforme sont HSVI et Q-learning. Toutefois, la liste est étendue à d'autres algorithmes de l'état de l'art.
| A* | Backward Induction | HSVI | MCTS | PBVI | Perseus | Q-Learning | REINFORCE | SARSA | Value Iteration | |
|---|---|---|---|---|---|---|---|---|---|---|
| MDP | 🚫 | ✅ | ✅ | ❌ | 🚫 | 🚫 | ✅ | ❌ | ✅ | ✅ |
| serial MMDP | 🚫 | ✅ | ✅ | ❌ | 🚫 | 🚫 | ✅ | ❌ | ✅ | ✅ |
| belief MDP | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| serial belief MDP | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| hierarchical belief MDP | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| occupancy MDP | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| serial occupancy MDP | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| hierarchical occupancy MDP | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | 🚫 |
| OccupancyMG | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | 🚫 |
Legend : ❌ not implemented 🚫 not allowed ✅ implemented
Les schémas algorithmiques peuvent être vu comme des templates génériques. Chaque instance d'un de ces schémas constitue un algorithme à part entière. Les changements peuvent intervenir au niveau de la définition du problème ou dans la façon de représenter les fonctions de valeurs.
HSVI algorithmic scheme
The general algorithmic scheme of HSVI is represented by the diagram below. To define an instance, this one requires to define the notions of state , action , lower bound and upper bound .
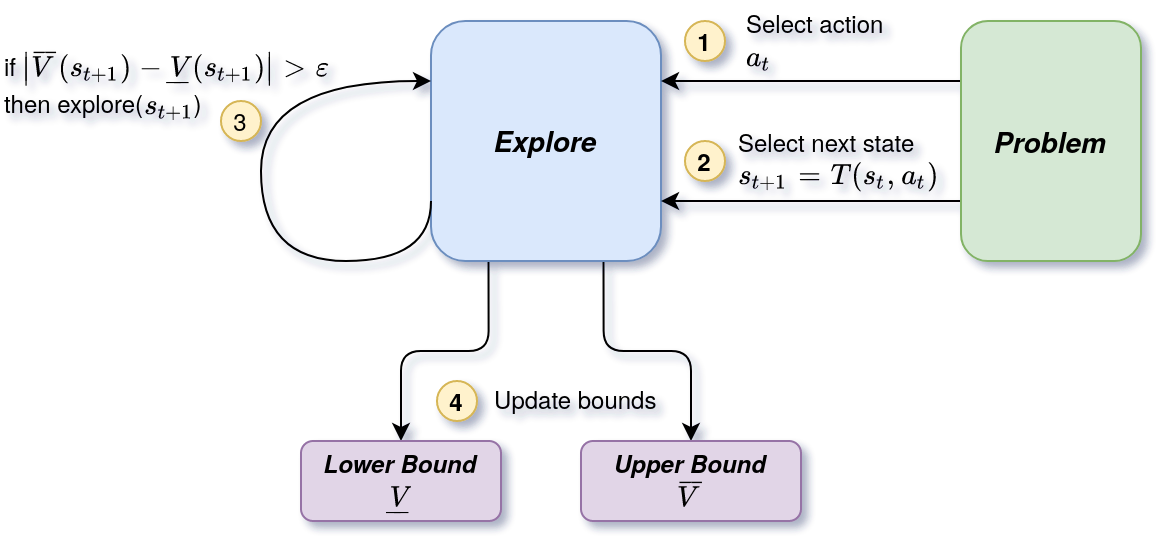
Example : An instance of HSVI is the oHSVI algorithm. This instance allows to solve a Dec-POMDP formulated as an occupancy-state MDP. The state type in this case is an occupancy state, noted . The action type is a set of individual decision rules, denoted . The lower bound is represented by a set of hyperplanes and the upper bound by a set of points.
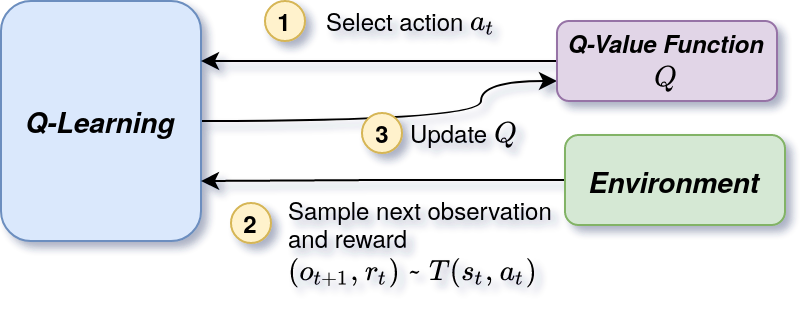
Q-learning algorithmic scheme
The general algorithmic scheme of Q-learning requires the definition of the notions of state, action and action value function (Q-value).